Hadoop 由 Apache Software Foundation 公司于 2005 年秋天作为 Lucene 的子项目 Nutch 的一部分正式引入。它受到论文 MapReduce 、GFS 与 Bigtable 的启发。
Hadoop 具有高可靠性、高扩展性、高效性和高容错性。Hadoop 主要由以下四部分组成:HDFS,一个高可靠、高吞吐量的分布式文件系统;MapReduce,一个分布式的离线并行计算框架;YARN,作业调度与集群资源管理的框架;Common,工具模块,支持配置、RPC、序列化机制、日志操作等。
部署规划
| 主机名称 | IP | HDFS | Yarn | 内存 |
|---|---|---|---|---|
| hadoop-01 | 192.168.226.137 | NameNode SecondaryNameNode DataNode | ResourceManager NodeManager | 1G |
| hadoop-02 | 192.168.226.138 | DataNode | NodeManager | 1G |
| Hadoop-03 | 192.168.226.139 | DataNode | NodeManager | 1G |
网络配置,创建用户



安装 JDK 和 Hadoop
解压二进制资源包,配置环境变量
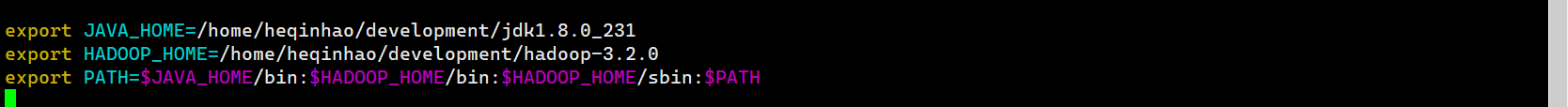
验证安装


设置防火墙、修改 hosts
环境与用户配置
hadoop-env.sh

start-dfs.sh

start-yarn.sh

参数配置
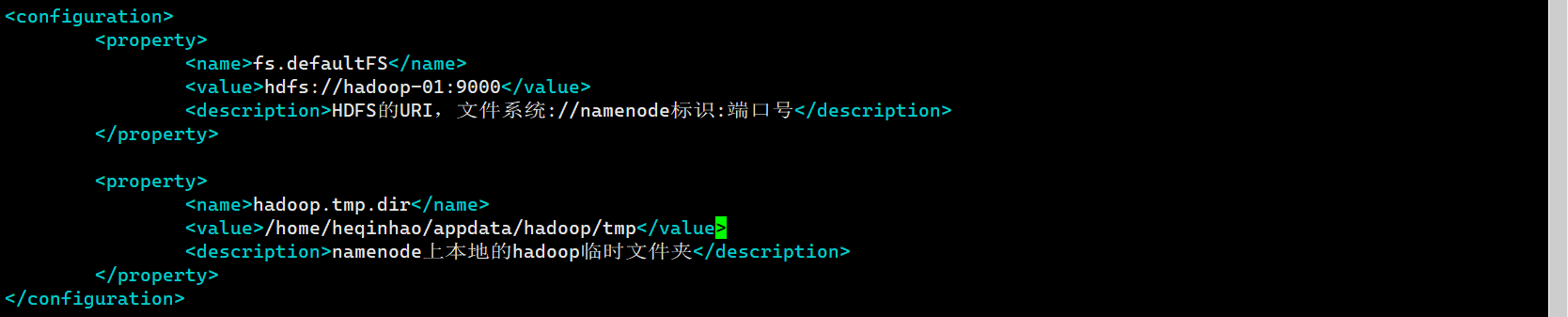
core-site.xml
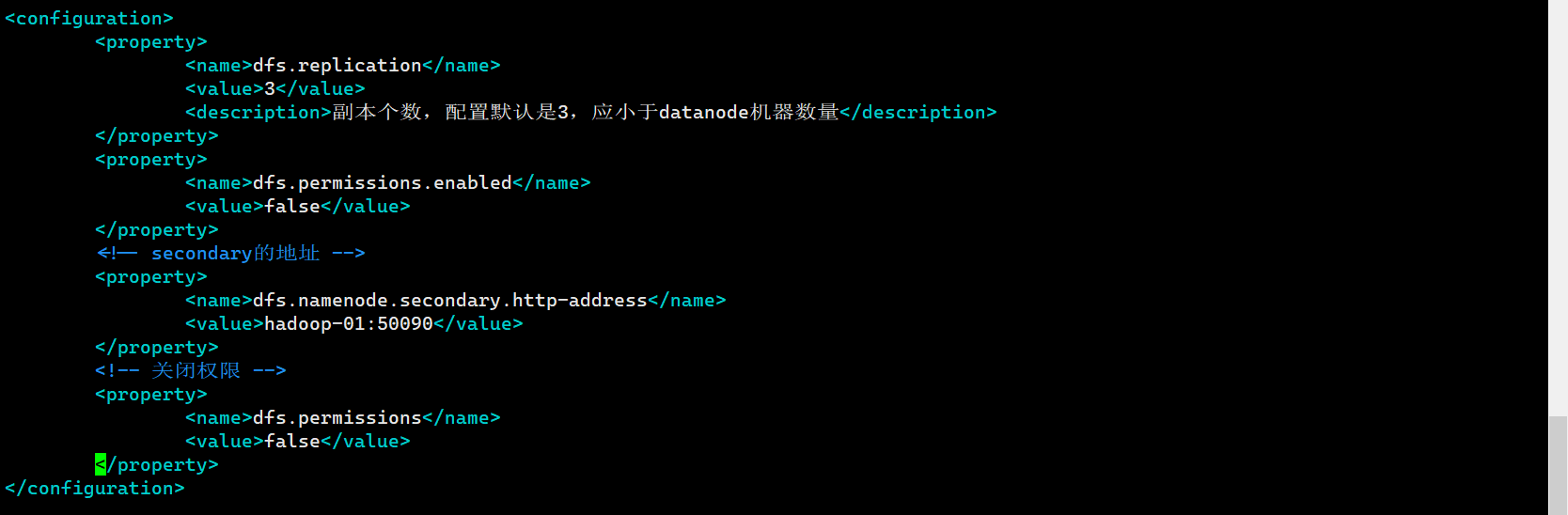
hdfs-site.xml

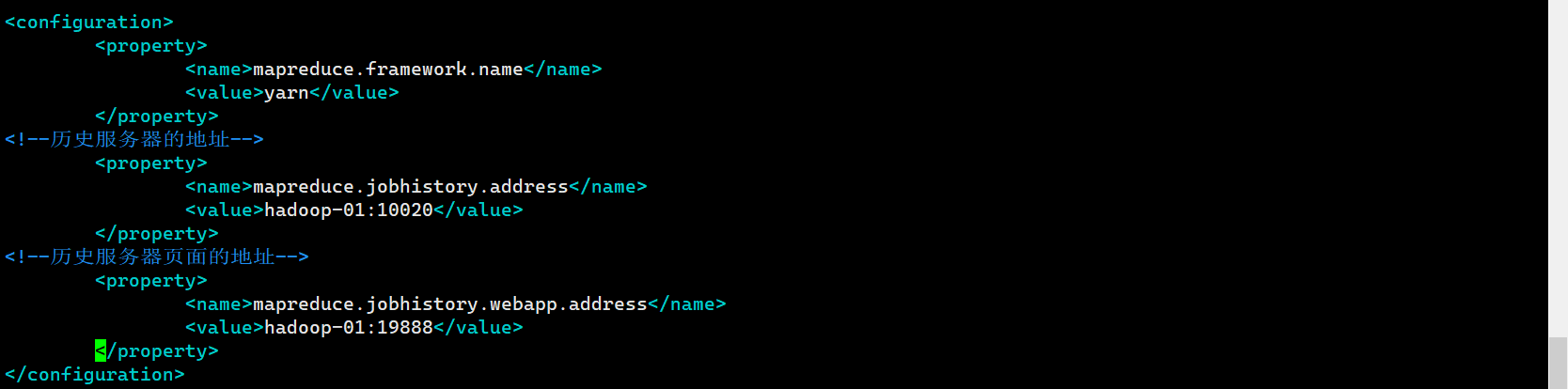
mapred-site.xml

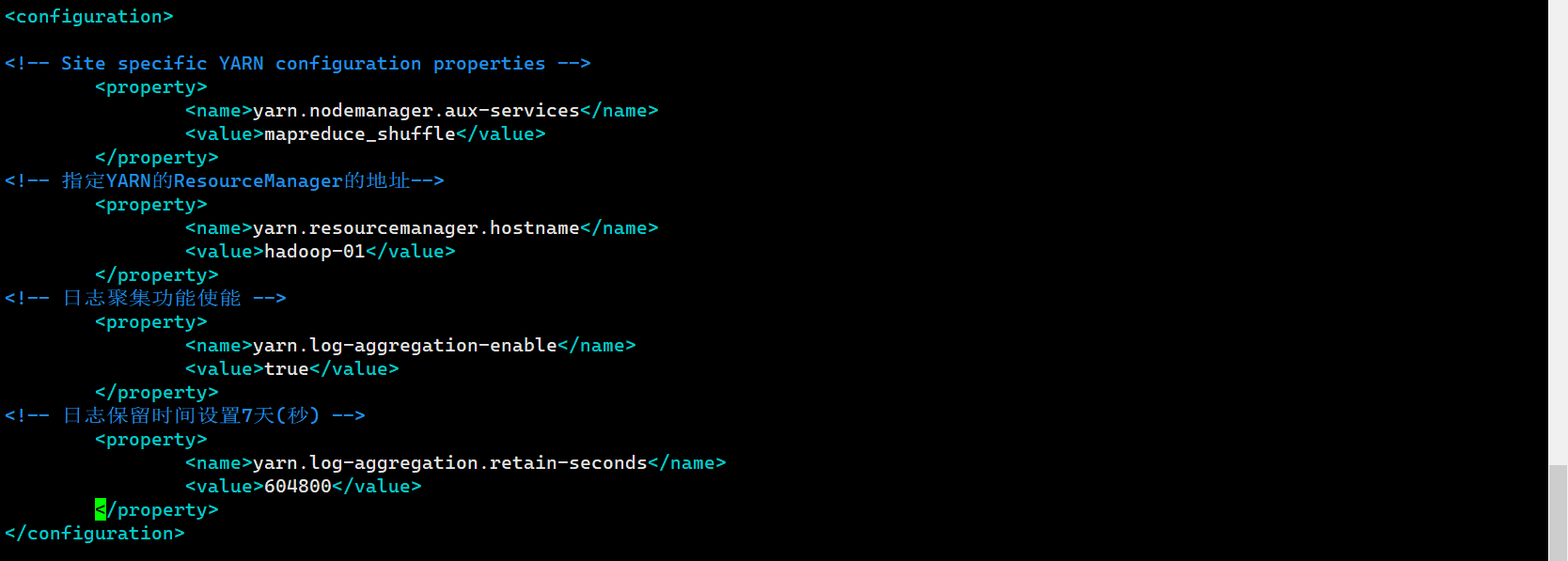
yarn-site.xml

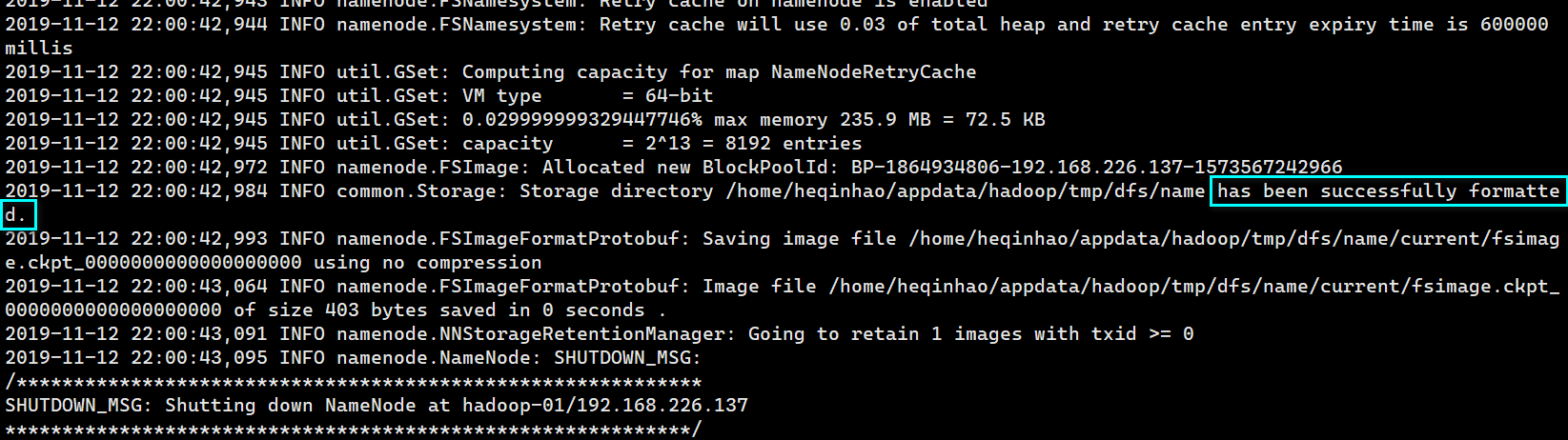
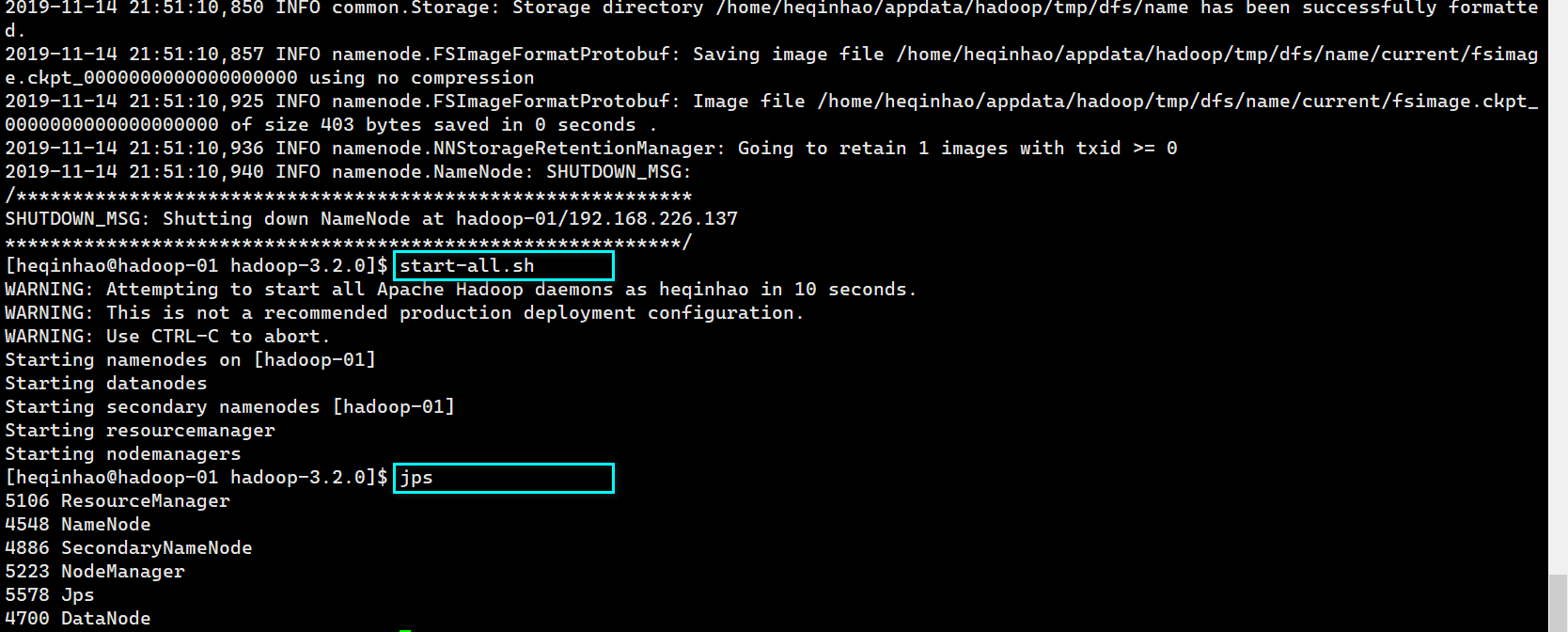
格式化 namenode

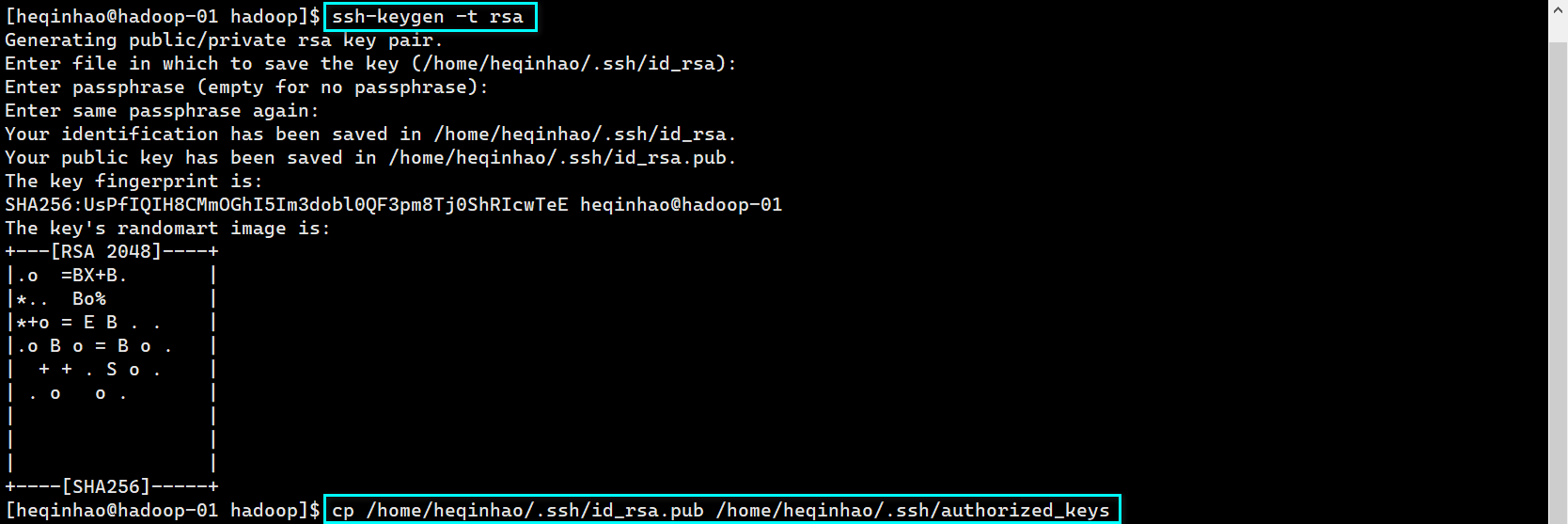
ssh 免密登录
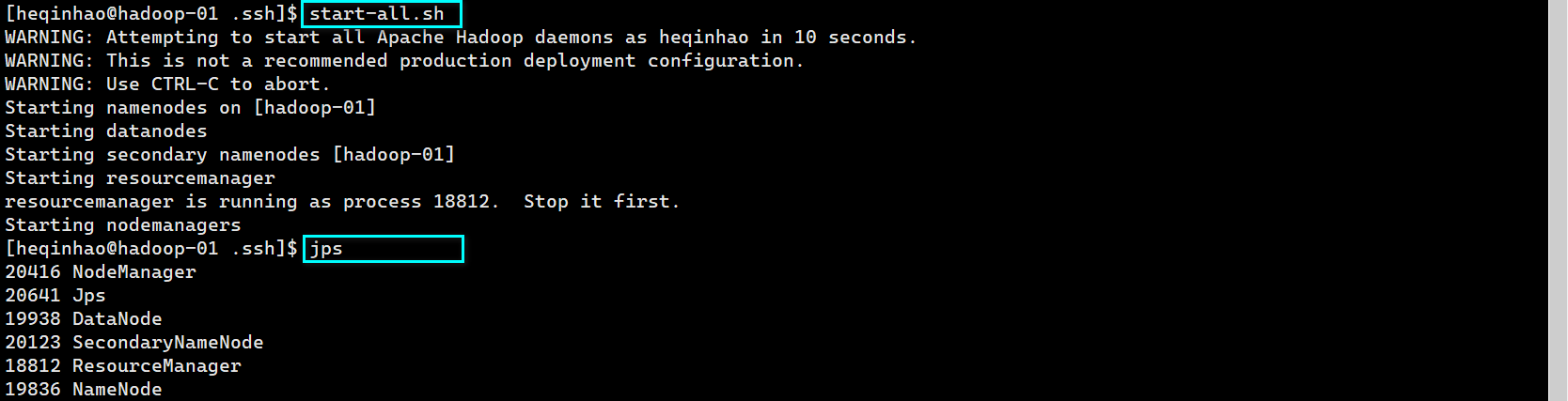
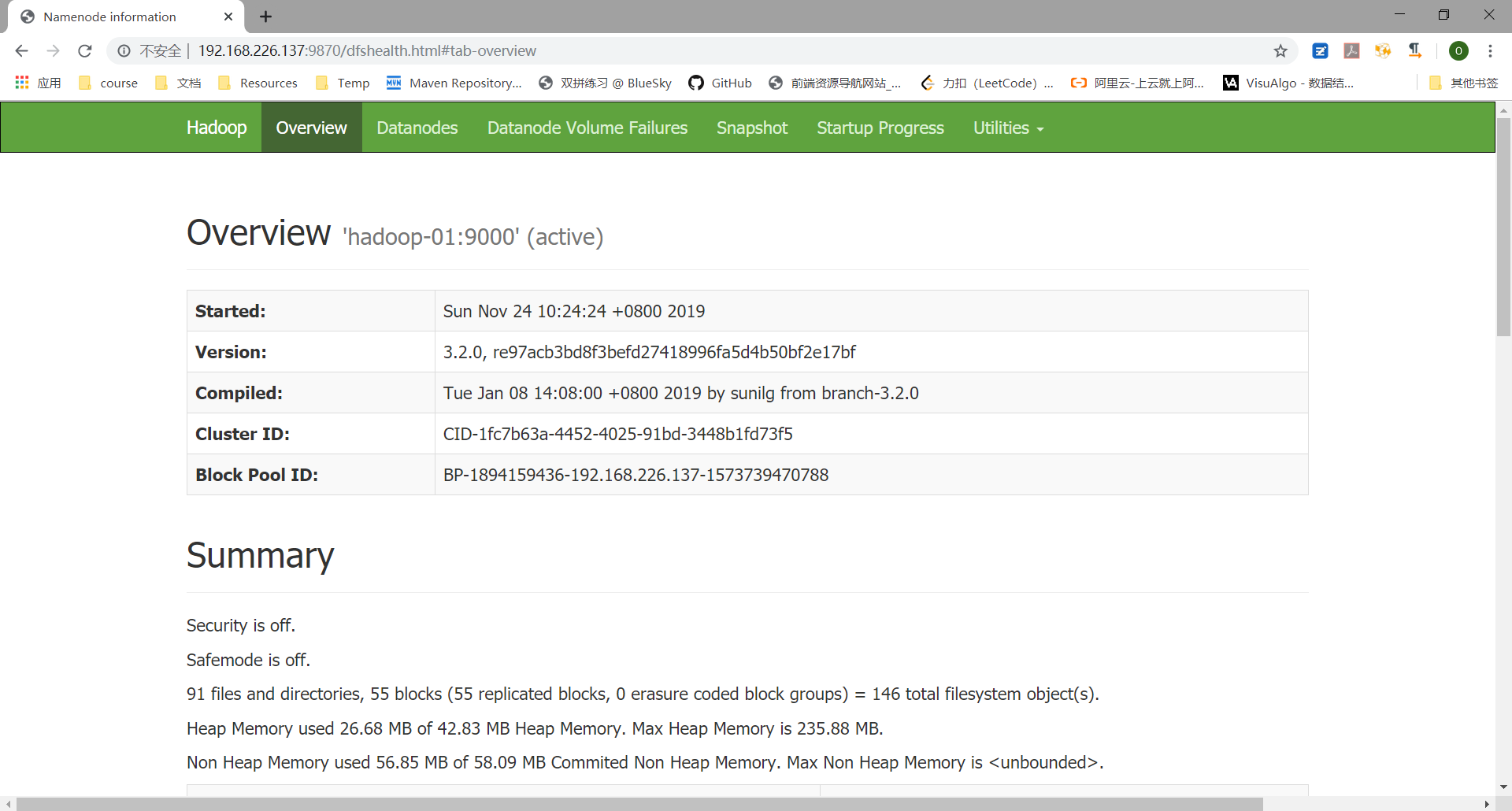
启动 Hadoop
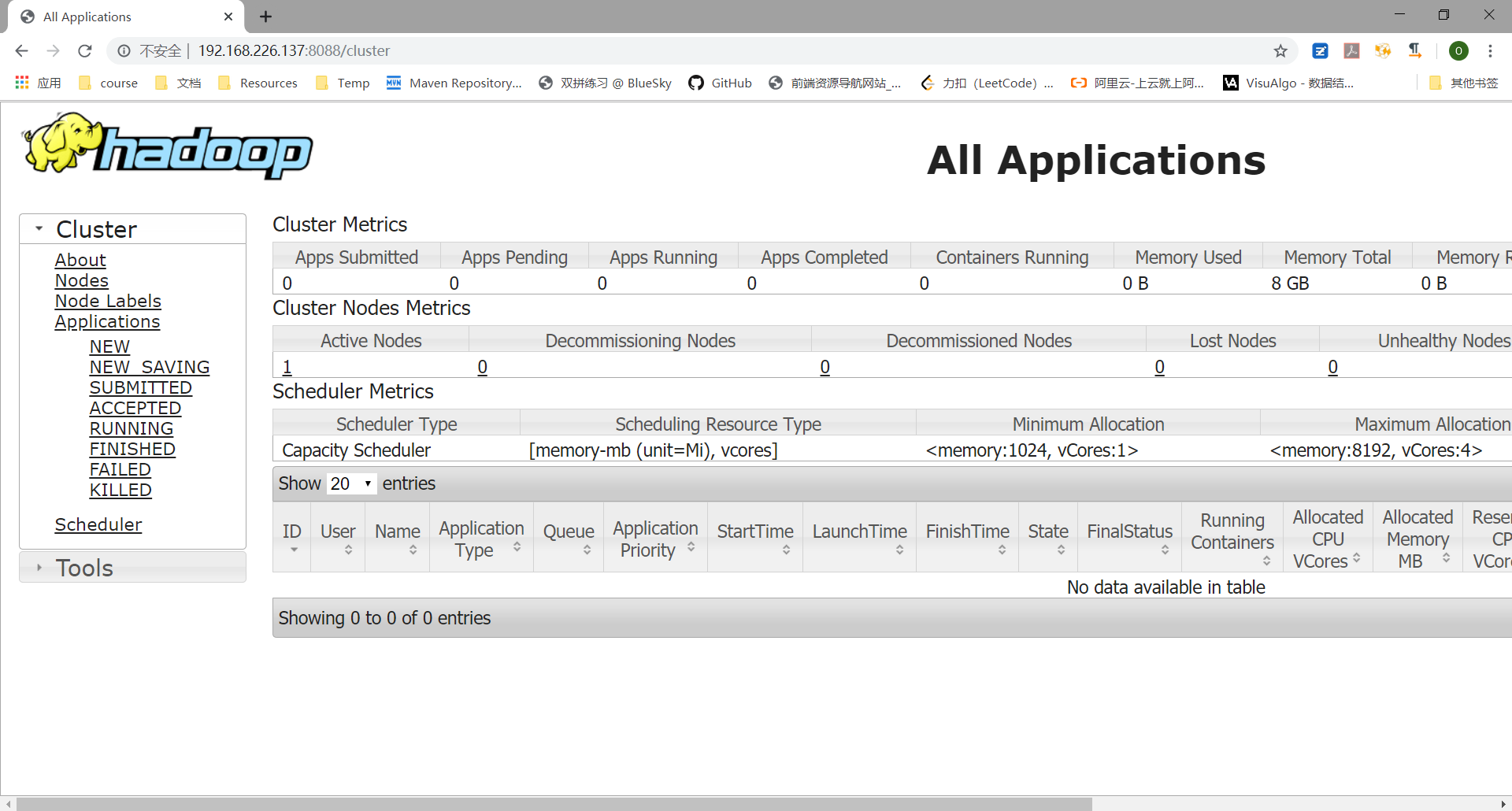
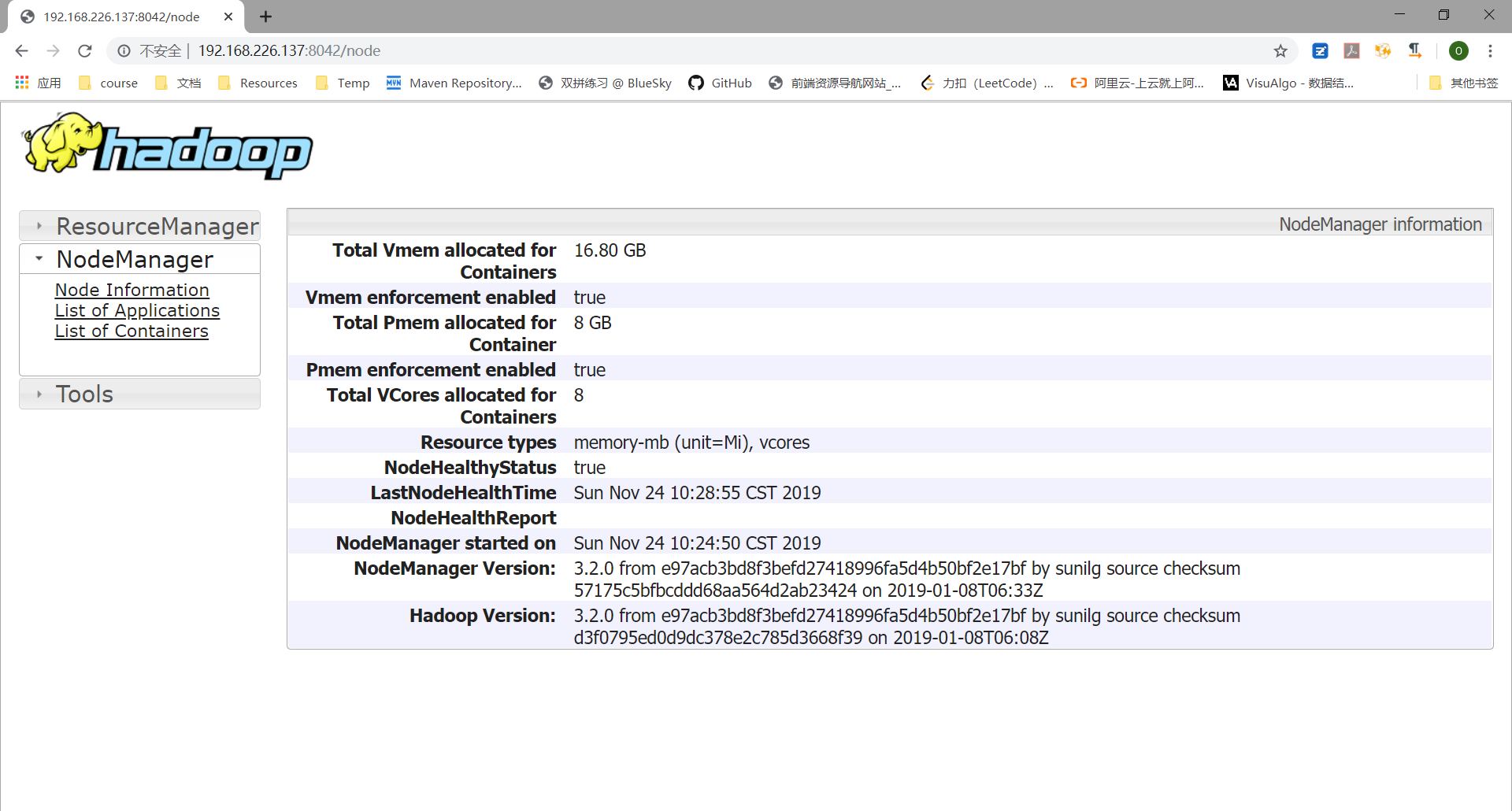
用 hadoop-01 克隆两台虚拟机
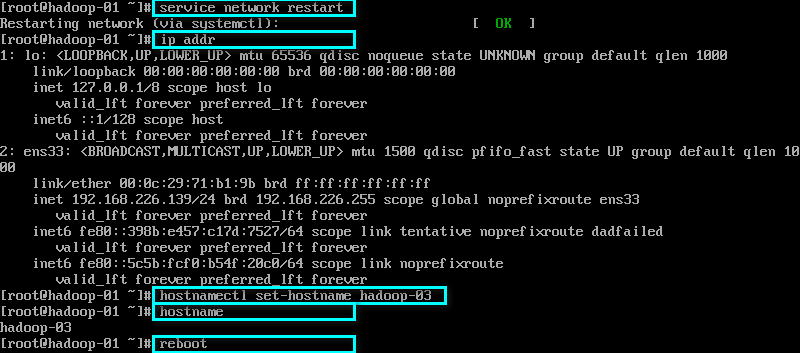
配置网络,修改主机名
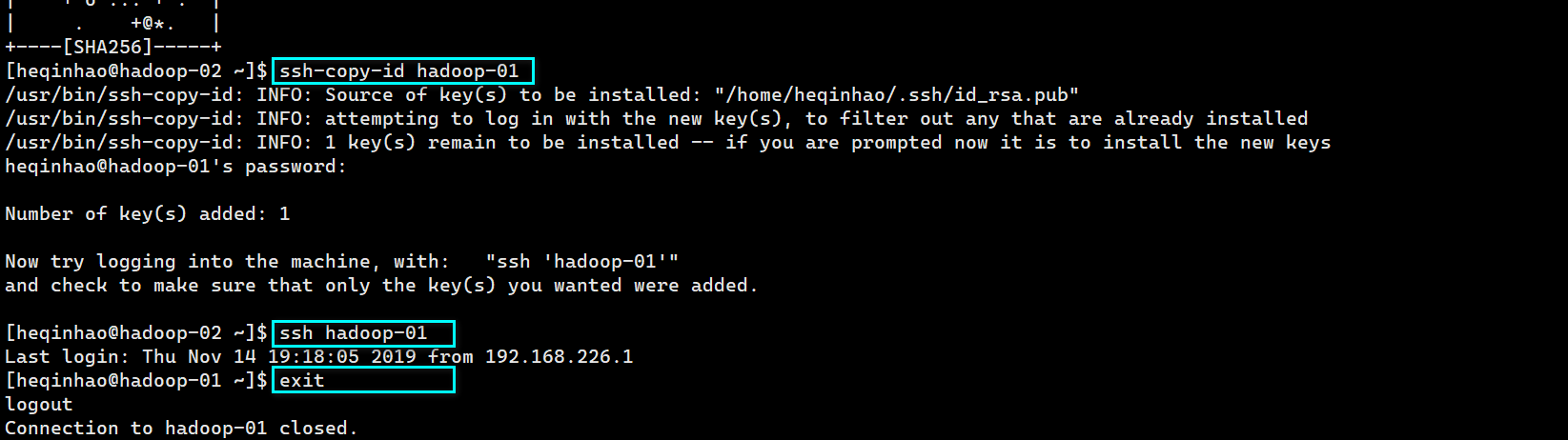
分别添加 ssh 公钥

修改参数
workers

hdfs-site.xml
yarn-site.xml
mapred-site.xml
格式化 namenode 并启动


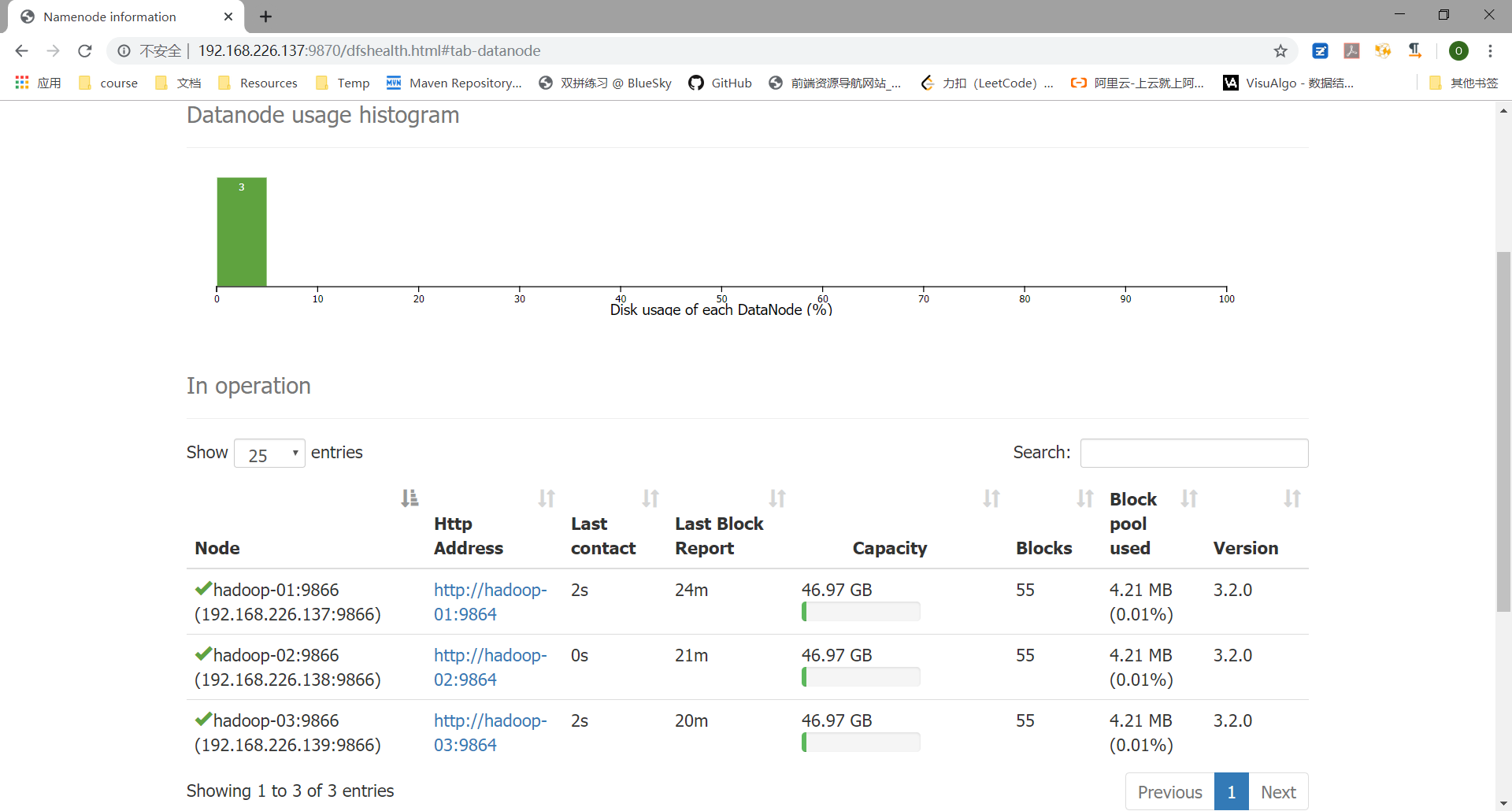
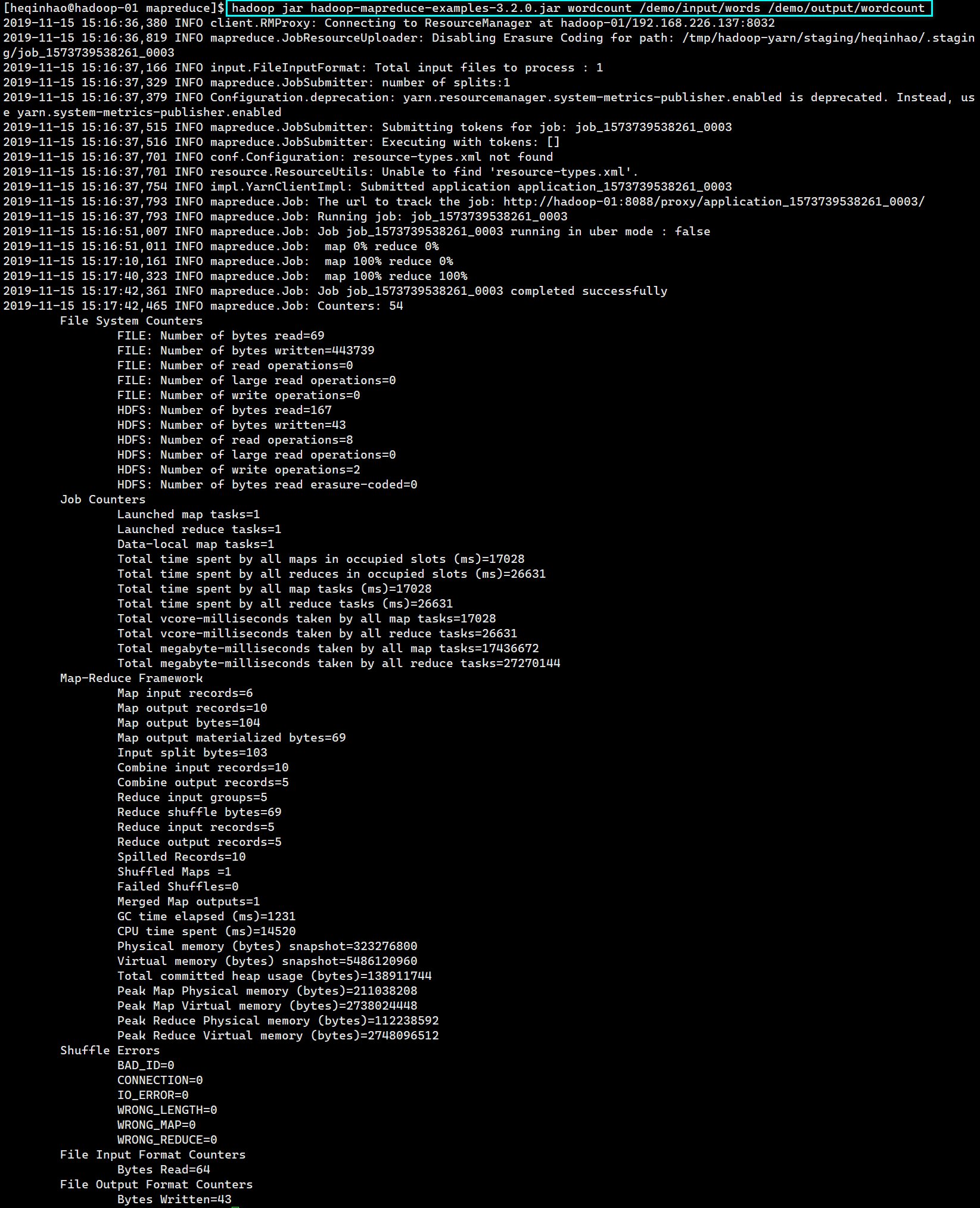
测试 wordcount 实例
创建测试文件

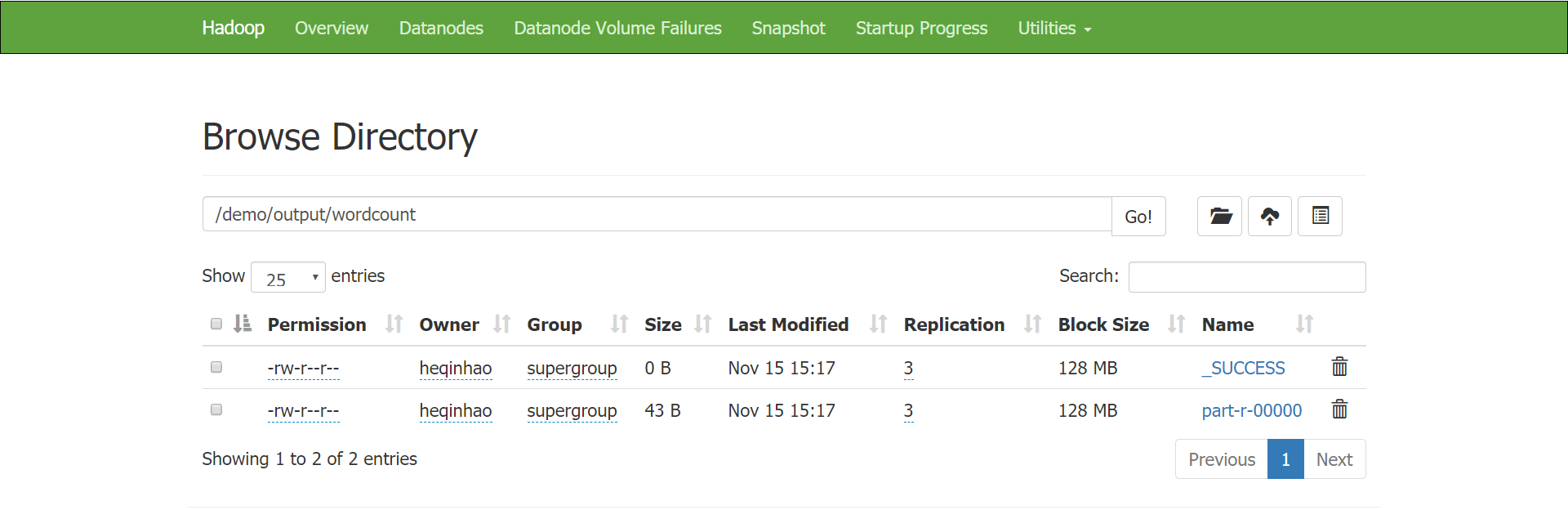
执行程序
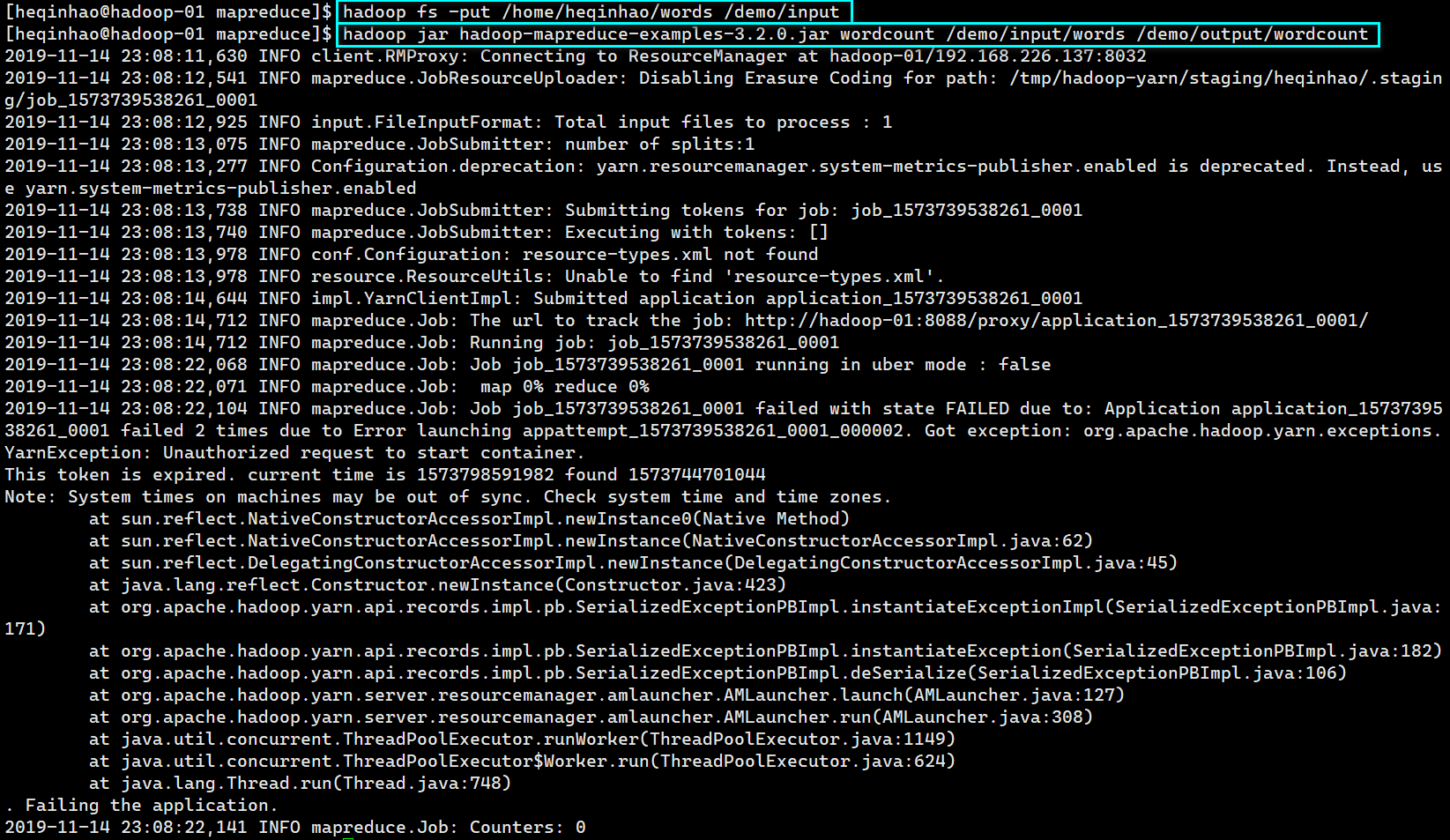
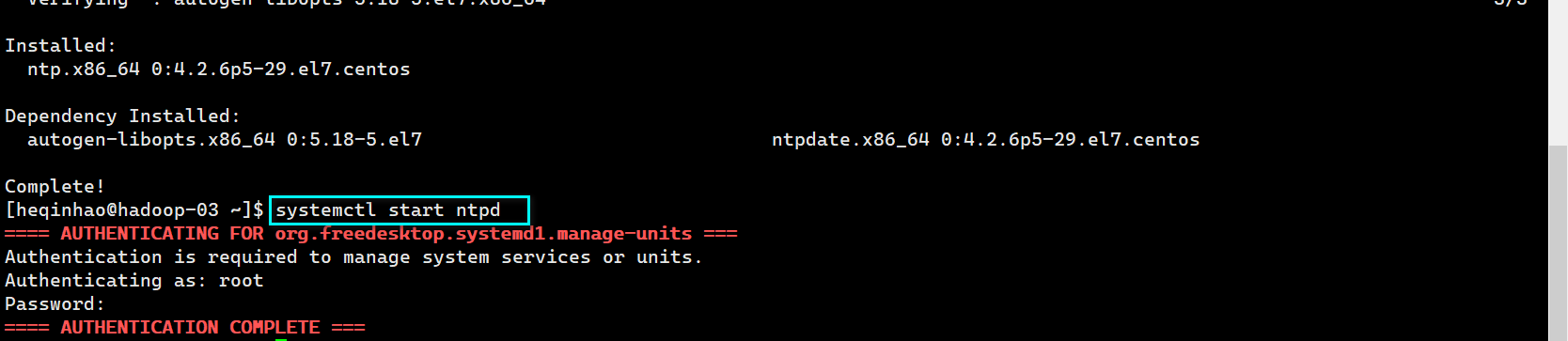
同步时间
再次执行
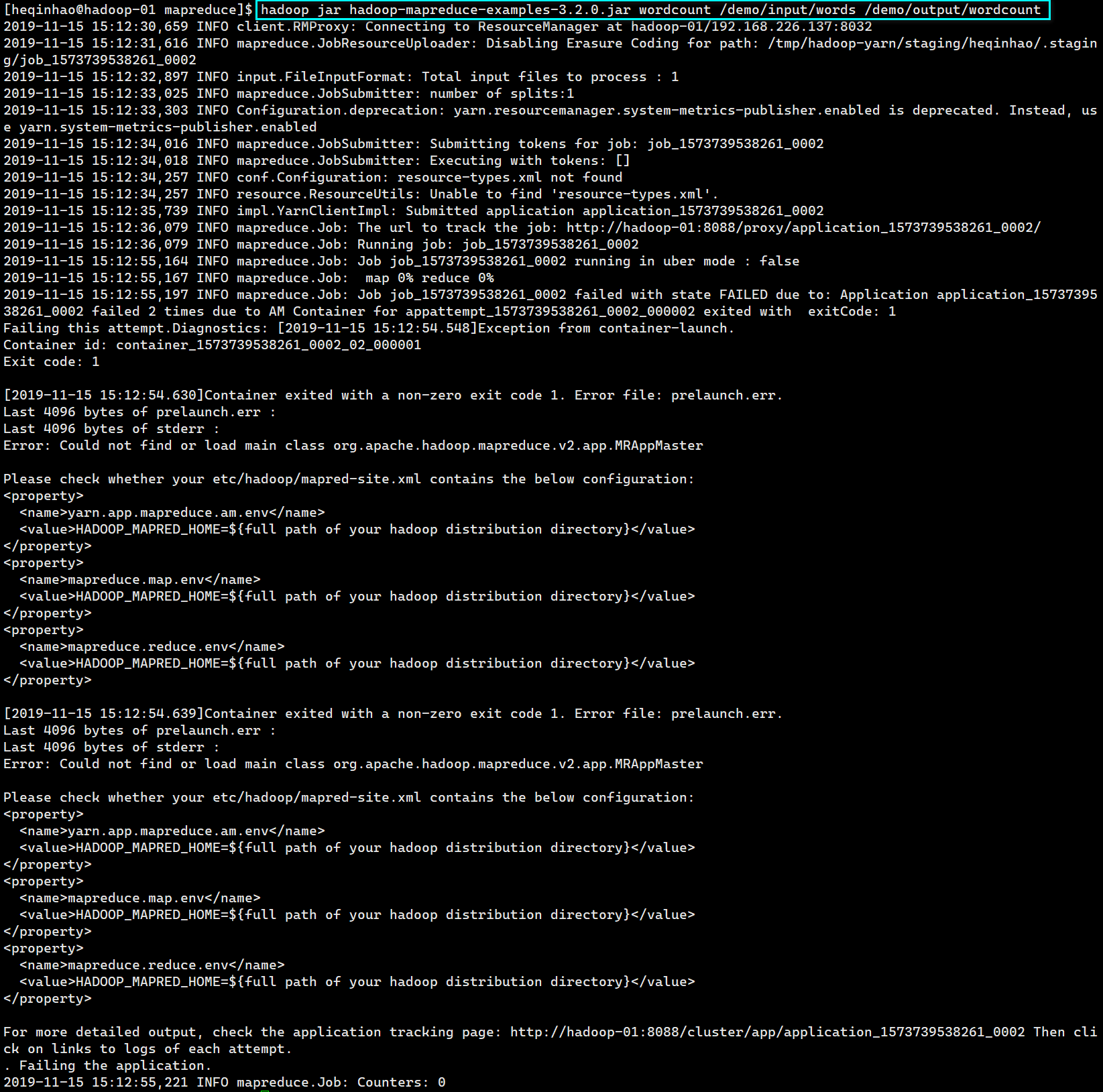
修改 mapred-site.xml
再次执行